
Agentic AI can reason, plan, and act across multiple systems. But moving from proof of concept to safe production depends less on the model itself than on the reliability, accessibility, and security of the supporting data and infrastructure.
In this webinar, Star Information Security and AI Manager Maksym Tsivyna explores how agentic AI changes data governance requirements, exposes weaknesses in legacy infrastructure, and what organizations need before deploying autonomous AI systems on operational data.
Why AI governance begins with data
Traditional software follows rules written by developers. Given a particular input, it performs a defined action and produces a predictable output. Its logic can usually be traced through the code, tested, and corrected. Machine learning works differently. Instead of specifying every rule, teams provide examples and allow the system to identify patterns within them. The quality, representativeness, and integrity of those examples directly shape the model's behavior. Data does more than serve as an input. It shapes how the model understands and interacts with its environment.

A well-known example is Amazon’s experimental AI recruiting tool. The model was trained on approximately 10 years of historical hiring information. That data reflected an existing gender imbalance in technical roles, so the system learned patterns that disadvantaged women. It penalized resumes containing the word “women’s” and downgraded graduates of all-women’s colleges. Amazon ultimately abandoned the tool. The model had learned from the data it was given, but the data and governance process had produced an unacceptable outcome.
This example demonstrates that even technically accurate data can be unfit for decision-making. Historical data often carries bias, gaps, or assumptions that should not drive future outcomes.
The same principle applies throughout the AI development lifecycle and after deployment, when live data continues to influence how the system performs. Changes in that data or its operating context can produce unexpected outputs, which is an especially serious risk when agentic systems can act on those outputs autonomously.
Monitoring for data and context drift is a continuous responsibility. It does not end once the system is deployed.
Why agentic AI raises the stakes
Conventional AI typically receives an input and returns an output for human review. An agent can go further: discovering information, using tools, updating systems, and triggering actions across other applications or agents. The data pipeline, therefore, moves from a linear process to a dynamic network operating at machine speed, reducing the time between a data issue and its real-world consequences.
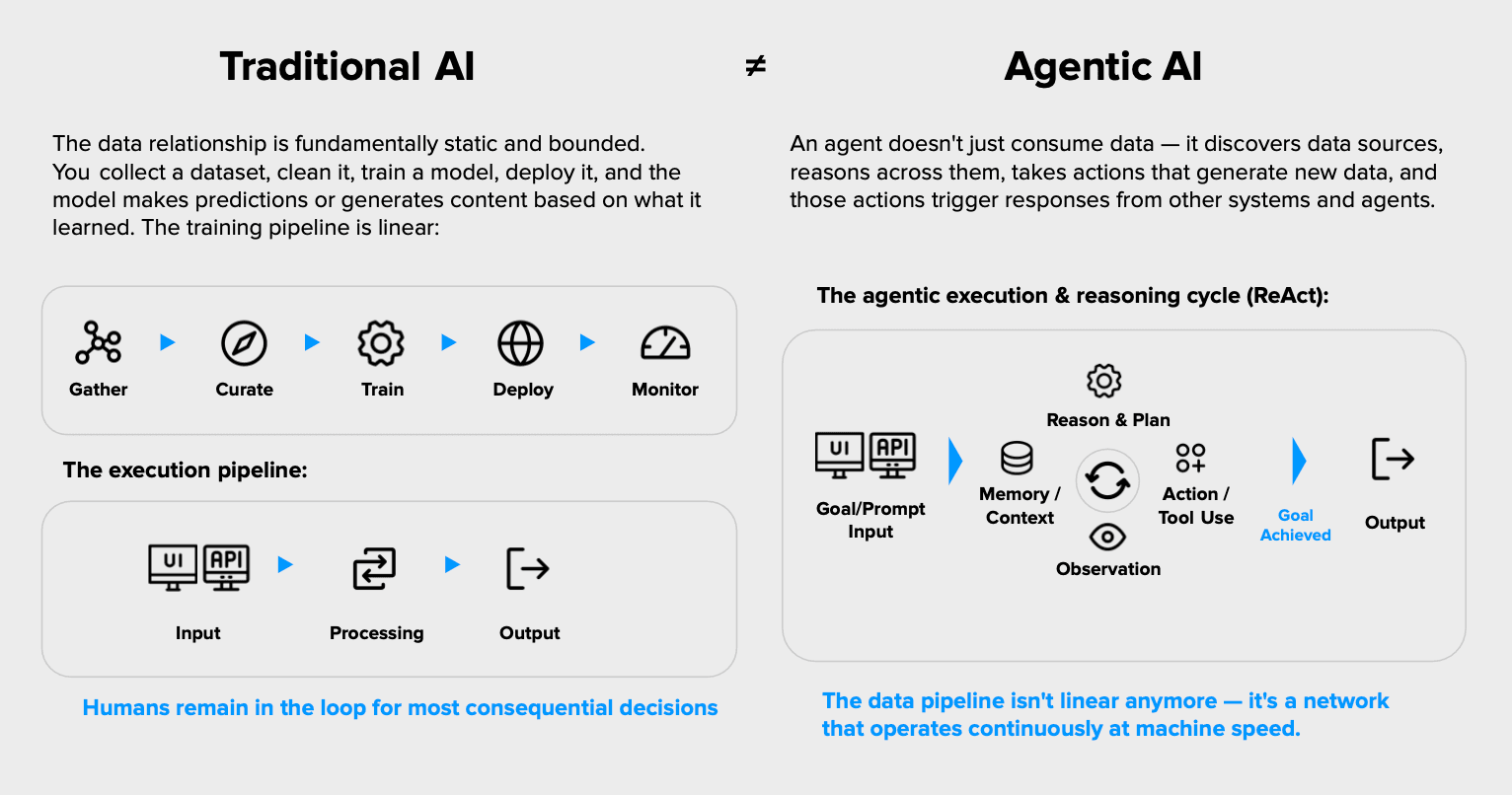
A conventional model might produce a poor recommendation that a person can question or reject. An agent can act on the same flawed information immediately. It may change a record, trigger a transaction, or instruct another system before anyone has reviewed what happened.
In the first case, bad data means bad recommendations that a human could ignore. In the second case, bad data means bad actions that have already been executed before anyone notices.

Maksym Tsivyna
Information Security & AI Manager at Star
The risk increases when autonomy is combined with incomplete context, excessive permissions, or unreliable infrastructure.
The infrastructure gap: When AI moves from analysis to action
Most enterprise infrastructure was designed for human-led workflows rather than autonomous agents. As agentic AI moves from analyzing data to acting on it, the demands placed on underlying systems change fundamentally. Much of today’s data infrastructure was built for periodic reporting and analysis, not for systems that make decisions and take action continuously.
Closing this gap means ensuring that data is sufficiently current, reliable, traceable, and secure for an agent to act on without constant human intervention. This is one of the central challenges in building agentic AI solutions that can be trusted to operate autonomously.
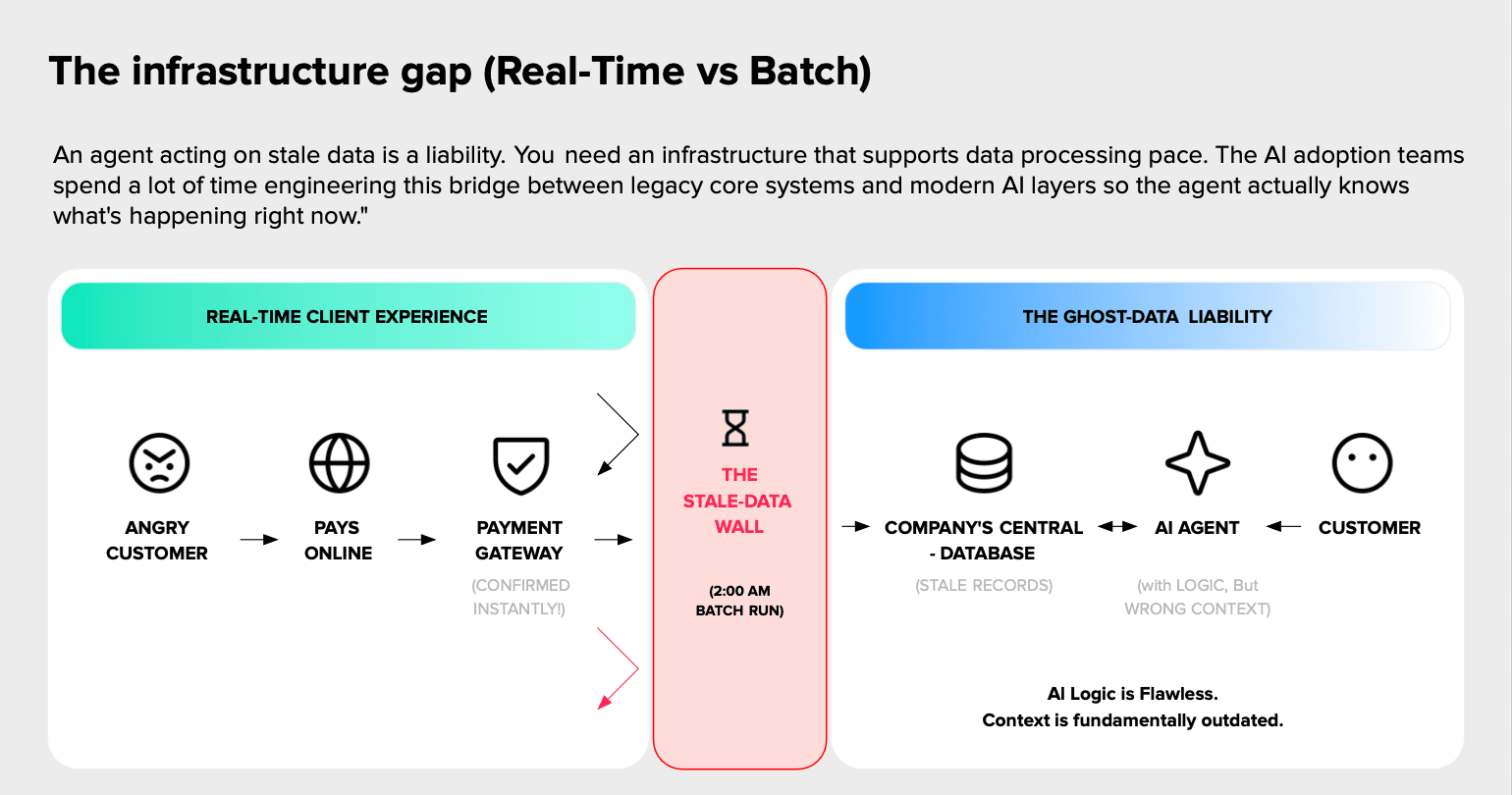
Consider a customer who pays an outstanding bill online. The payment gateway confirms the transaction instantly, but the company’s central database will not update until the next batch run. An agent reading that database may continue treating the account as overdue. The agent might send an incorrect reminder, restrict a service, or trigger another action based on outdated information. The reasoning may be sound, but the context is no longer current. This creates a ghost-data liability: outdated information can persist in one part of the organization even after it has been updated elsewhere.
Data location also affects readiness. Cloud and edge architectures involve different trade-offs across scalability, latency, offline operation, cost, privacy and regulatory compliance. For regulated or safety-sensitive products, the decision about whether data remains local or moves to the cloud may also be shaped by privacy, security, and compliance requirements. The right architecture depends on the use case. The essential requirement is reliable, timely, and secure access that matches the agent’s operational speed.
Four levels of infrastructure readiness for agentic AI




Not every workflow needs Level 4 infrastructure. An internal research assistant may work effectively with batch information and human approval, while agents involved in payments, healthcare, cybersecurity, or connected products may require real-time data and automated controls. Organizations should assess these requirements before investing heavily in model development.
The bottleneck is rarely the AI itself. It is the connection to existing infrastructure.
Maksym Tsivyna
Information Security & AI Manager at Star
The three pillars of data governance for agentic AI
There are three connected pillars that organizations should address when preparing data for AI: quality, accessibility, and security.
1. Data quality
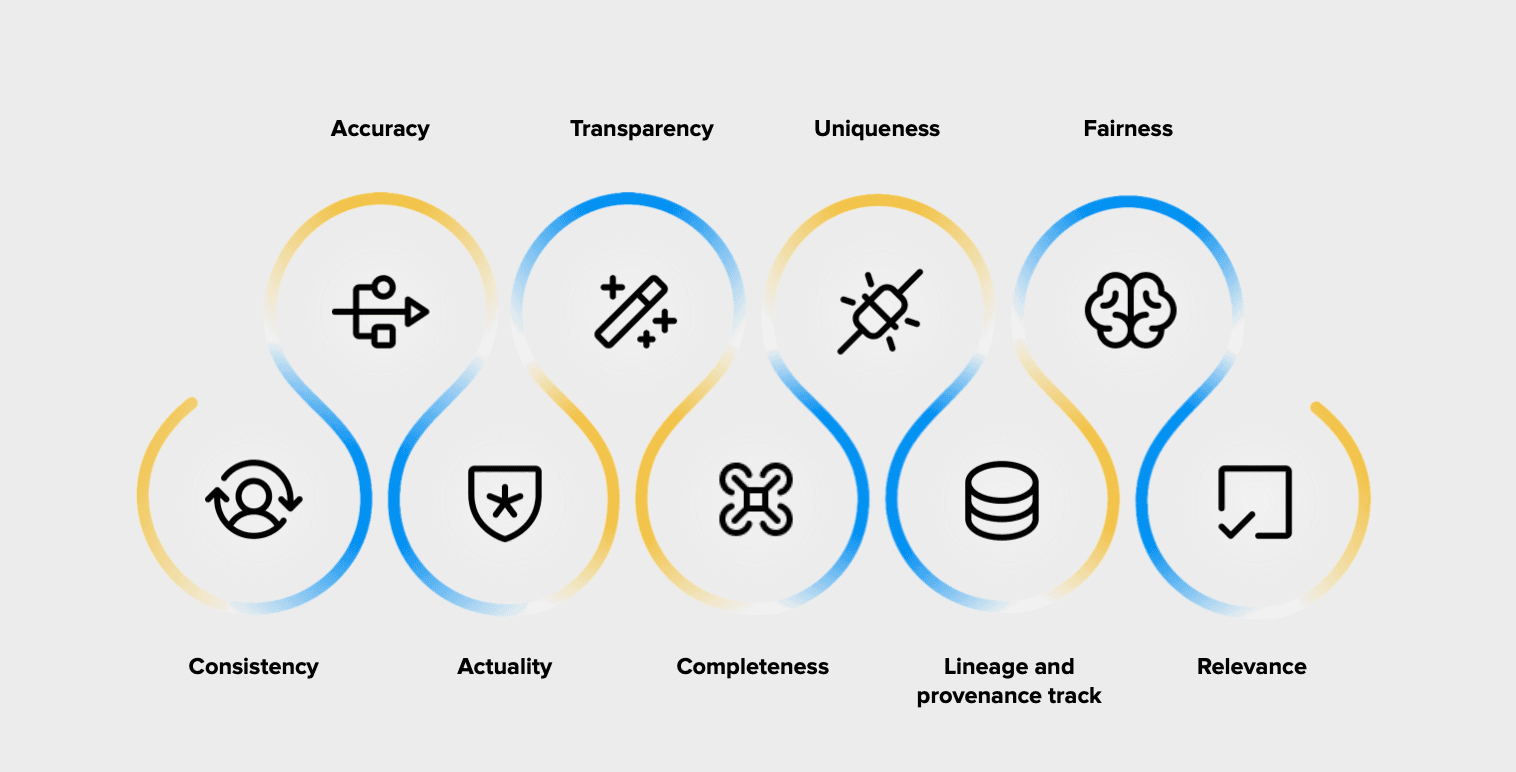
Data must be accurate, consistent, current, complete, and relevant to the task. Organizations should also consider uniqueness, fairness, transparency, and provenance. Lineage records show where information originated, how it changed, and which version was used. This is particularly important when an organization must explain an AI-supported decision or demonstrate control over a regulated process. Production monitoring should also identify changes in data characteristics, because performance during testing does not guarantee continued reliability.
2. Data accessibility
Accessibility determines whether the agent can reach the information it needs, at the right time, and in a form it can use. Agentic AI systems may interact with databases, APIs, Internet of Things devices, open-web sources, synthetic data, external services, and human input. Each source can introduce different formats, permissions, response times, and levels of reliability.
Development teams rarely have full visibility into every dependency, especially when third-party AI services or tools are involved. Organizations must determine how an agent should respond when a source is unavailable, delayed, or incomplete: whether it can continue safely, use an alternative source, request human input, or stop altogether.
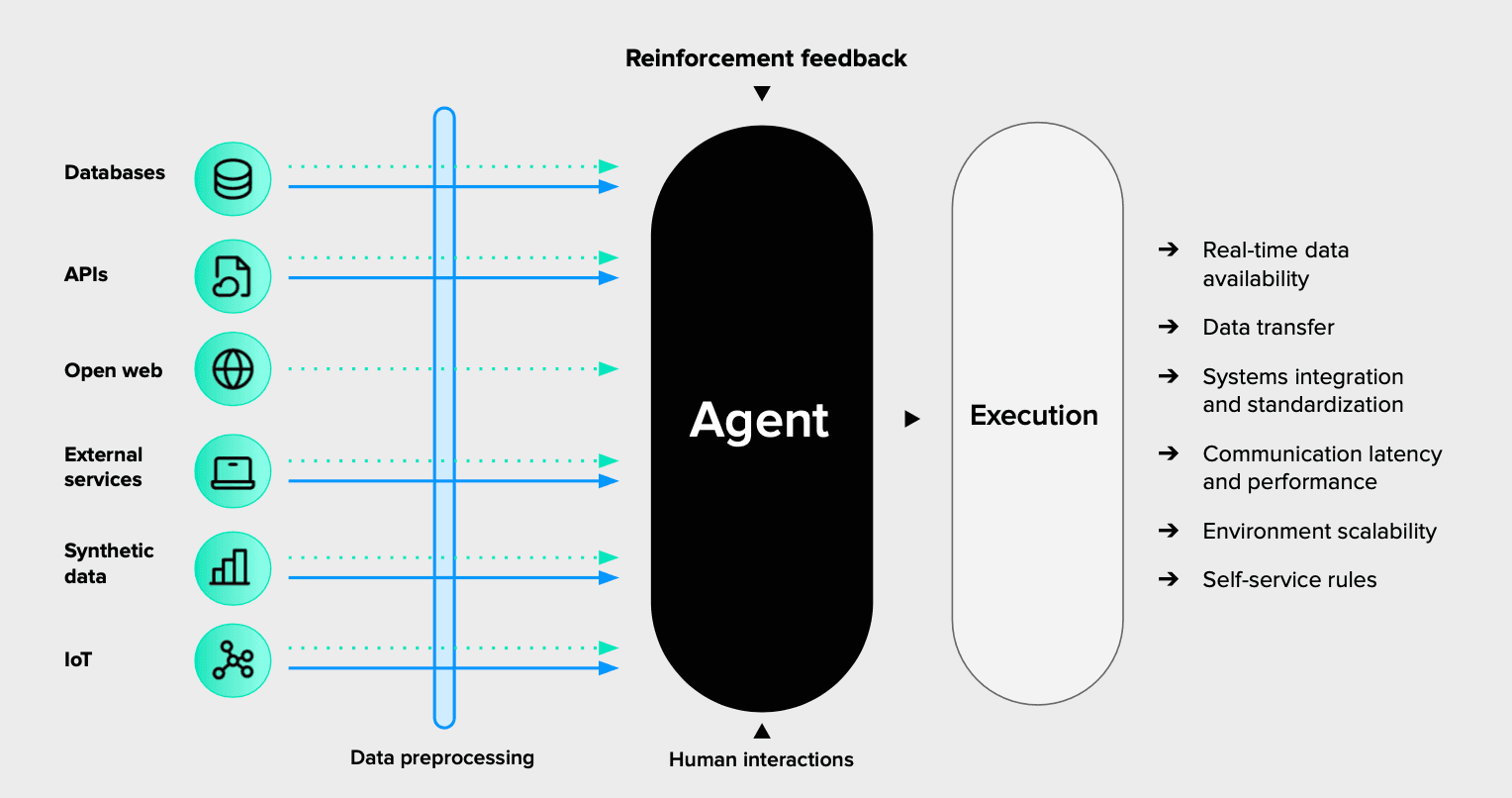
Accessibility depends on controlled access to relevant data and clear protocols for safe operation when information is missing.
3. Data security
The established security principles of confidentiality, integrity, and availability remain highly relevant to agentic AI. Confidentiality limits data access to authorized users, systems, and agents. Integrity protects data and connected systems from unauthorized or uncontrolled changes. Availability ensures that information and infrastructure remain accessible when required.
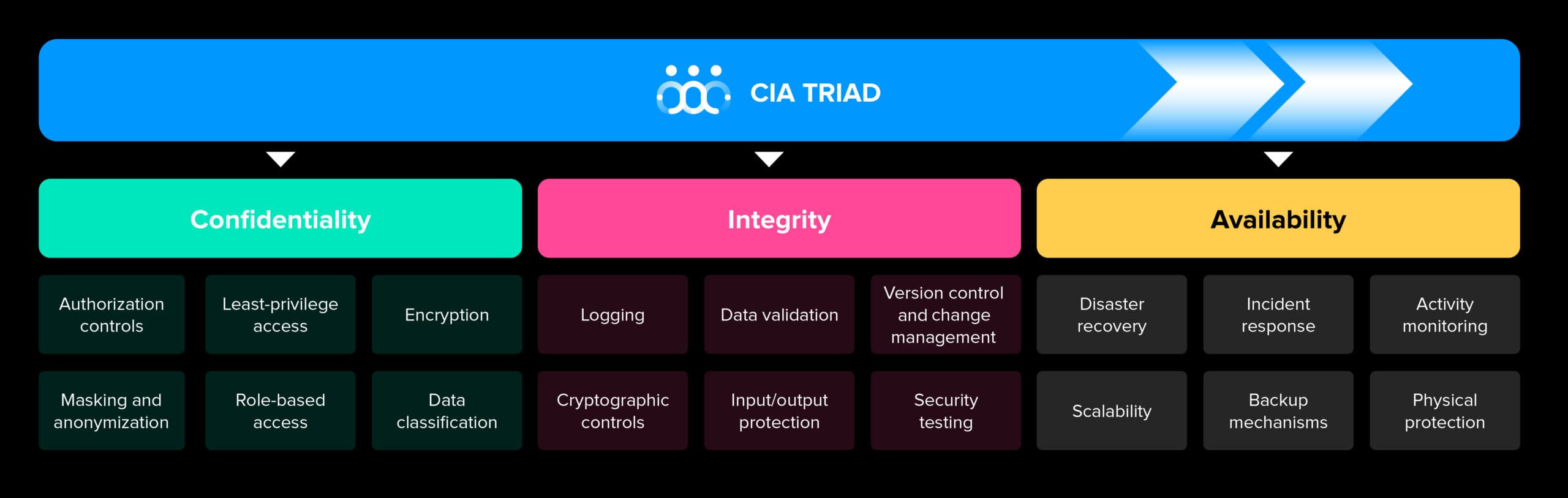
Controls can include least-privilege access, role-based authorization, encryption, data classification, masking, validation, version control, logging, monitoring, backup, and incident response. Many of these controls are standard in cybersecurity. The challenge is to adapt them for systems that interact with data more often and with less human oversight.
Regulation is catching up with agentic AI
Regulatory frameworks are evolving, but technology is advancing faster than the rules governing it. The EU AI Act classifies AI systems by risk and introduces requirements for governance, transparency, and oversight. However, many existing approaches were developed with predictive models in mind rather than agents that combine information and act across several systems.
Data protection requirements create similar questions. Consent and purpose limitation are easier to define when people control each stage of processing. They become more complex when an agent autonomously retrieves and cross-references personal data.
The same challenge appears across regulated industries. Sectors such as healthcare, financial services, and automotive are governed by their own sector-specific rules. These requirements continue to apply to agentic systems, even where they do not explicitly address agentic behavior.

Organizations should not wait for regulatory clarity before strengthening internal governance. Requirements are likely to become more detailed and stringent in the coming years, so organizations should start preparing today. A more resilient approach is to build governance that can adapt as requirements change. This means documenting intended use, assigning ownership, controlling approved data sources, maintaining records of system actions, and monitoring performance after deployment.
Organizations operating in regulated markets should also be prepared to explain and defend their approach. It may not be enough to state that a control exists. They may need evidence showing that it works throughout the AI lifecycle.
Practical starting points for secure agentic AI
Organizations do not need to develop their governance approach from scratch. Frameworks such as the NIST AI Risk Management Framework and ISO/IEC 42001, together with OWASP security guidance, provide a structured foundation that can be adapted to an organization's technology stack, processes, and risk profile.
A practical readiness process should cover six areas:

Staff awareness is a critical part of this process. Employees need clear guidance on which AI tools are approved, what information can be entered into prompts, and how to assess third-party or open-source components. Technical controls cannot compensate for a lack of organizational visibility into how AI is used.
Build the environment, not just the agent
Preparing for agentic AI requires more than selecting a model or integrating an API. Organizations need governed data, suitable infrastructure, effective cybersecurity, regulatory processes, and clear accountability. By connecting business strategy with technology execution, organizations can move beyond experimentation and deploy autonomous AI systems that operate safely within real-world products and processes.
Star supports organizations from initial strategy through implementation and ongoing operation. Contact our expert to see how we can help with your organization’s AI management system development, regulatory strategy, compliance implementation, market placement, and post-market support, alongside practical AI governance guidance and regulatory training.
Is your organization ready to deploy agentic AI safely?
Agentic AI depends on more than the right model. It requires reliable data, suitable infrastructure, clear governance, and controls that work across the complete AI lifecycle.
Star can help you assess your current readiness, identify gaps, and build the technical and regulatory foundations needed to move from experimentation to secure, scalable implementation.
FAQ's
Data governance for agentic AI is the framework for managing the quality, accessibility, security, ownership, and use of the data that autonomous agents rely on. It helps ensure agents act on accurate, current, and authorized information.





