The other day I was trying to hit a “perfect week” goal with my Apple watch. It’s amazing how this device has become a big thing for me, even though, frankly speaking, I’m not the fitness kind of a person. I try to close all rings every day, commit to all challenges, and rely on the watch to determine which type of sports activity I perform.
Such usage of wearable devices is not something new. In 2014, I took a data science course, and we used accelerometer and gyroscope data collected from smartphones to predict the subject's activity. The data was collected in 2012 from 30 subjects between 19- and 48-years-old, performing one of six standard activities while wearing a waist-mounted smartphone that recorded the movement data. Today, you can find this dataset on multiple websites, particularly on Kaggle as ‘Human Activity Recognition with Smartphones’.

It was quite a fun experience. The model’s accuracy was around 95% from a simple tree ensemble. In 2020, neural networks demonstrate state-of-the-art results in almost all areas, including time-series data from IoT sensors. Recurrent neural networks allow us to achieve incredible accuracy and perfectly predict not only overall activities, but individual gestures as well.
Nowadays, I have fewer fun things to do and a lot of grown-up things, like reports, presentations and tech talks. When I am on a stage or at a whiteboard, I typically gesticulate a lot. So I thought, “Why not embrace this trait and make the presentation process less boring?” What if I wear a magic hat and control a presentation using gestures only? Can we marry an Apple Watch, Deep Learning, finger-snapping and a presentation? Let’s see how it works.
Overview
We will start with a simple architecture, transferring IoT data over the network to a laptop with a neural network responsible for gesture recognition. Once it’s ready, I’ll show how to train the model in the cloud using AWS Sagemaker and run it on the edge directly on your phone.
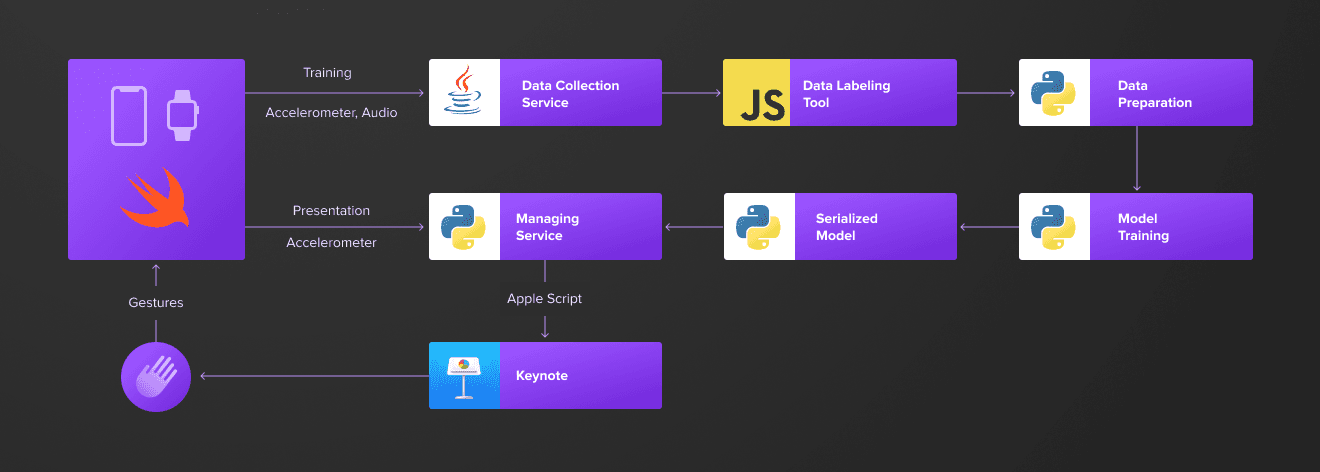
In the beginning, I will use just one gesture — a finger snap, that moves Keynote to the next slide. Later on, we can extend our list, combining finger snaps and hand waves to navigate back and forth in the presentation.
Data analysis
As is usually the case in the real world, I started with an idea which needed to be proven with data. I wanted to check if finger snaps are visible in the data and can be differentiated from other gestures, so I hastened to prototype a watch application that collects accelerometer data. I’m not proud of my swift skills, but for the sake of consistency, you can find the source code on Github.
Accelerometers measure changes in velocity along the x, y, and z axes.
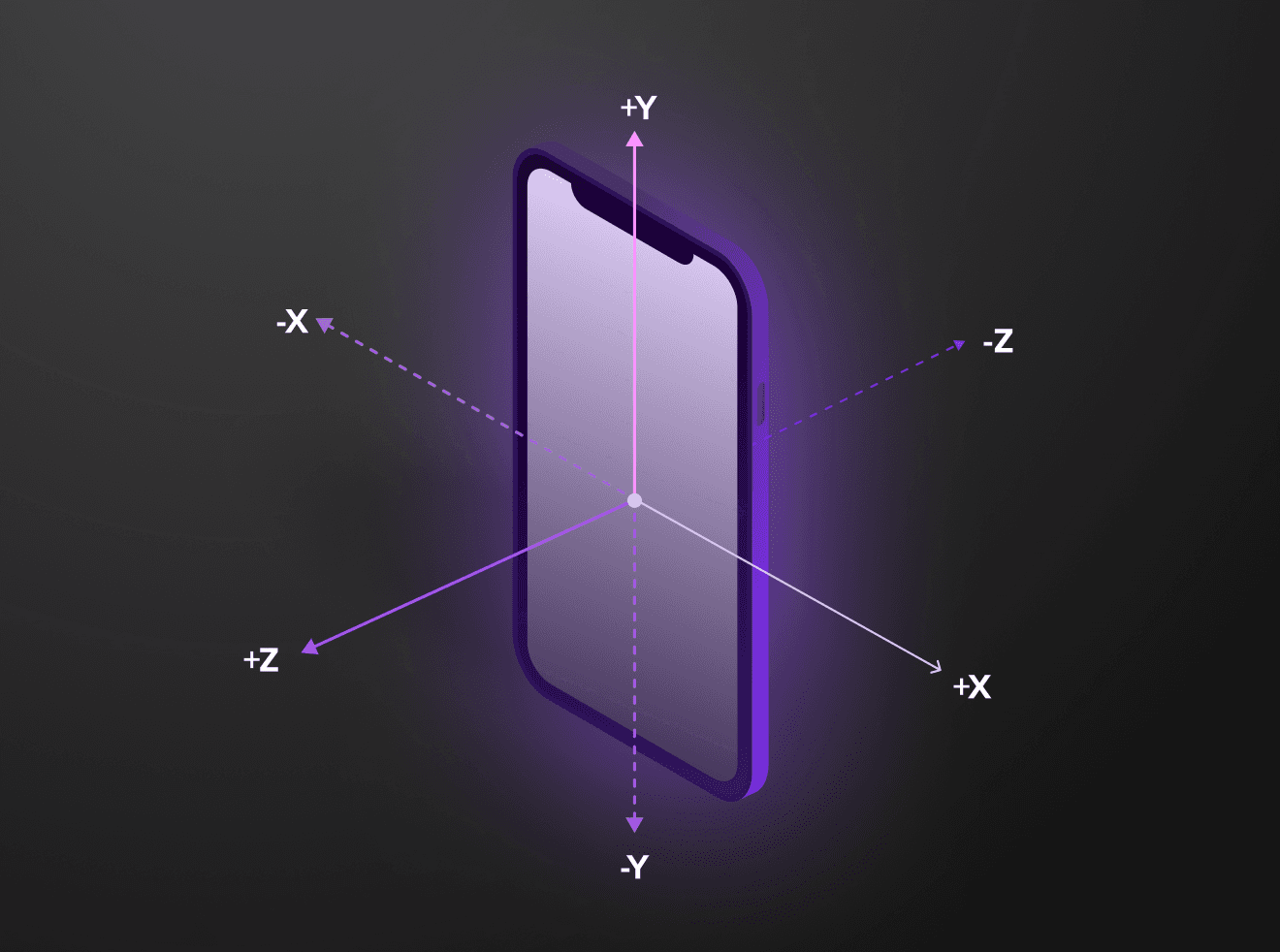
In iOS world, CMMotionManager reports movement detected by the device's onboard sensors. It provides access to accelerometer, gyroscope, magnetometer and device-motion data. I’ll only be using the accelerometer data at the beginning, to keep things simple. You might also want to try device-motion data. It offers a simple way for you to get motion-related data for your app. Raw accelerometer and gyroscope data must be processed to remove bias from other factors, such as gravity. The device-motion service does this processing for you, giving you refined data that you can use right away.
The frequency of the data updates depends on the devices, but typically it’s capped at 100 Hz. Higher frequency means better resolution, but it results in larger volumes of data and higher battery usage, so we need to find a balance that allows us to identify snaps with a reasonable volume of data.
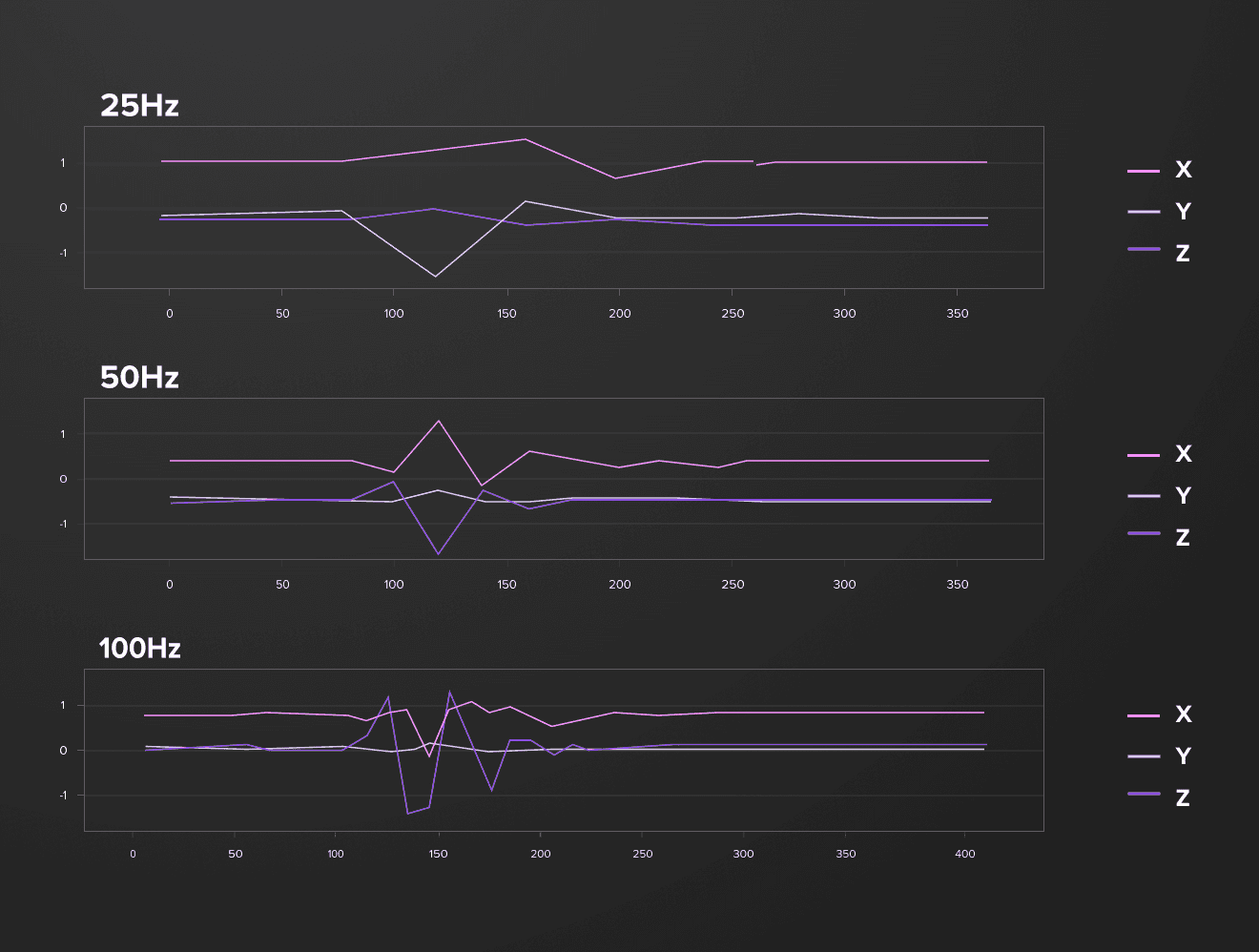
On the above chart you can see how snaps look with various frequency (25Hz, 50Hz, 100Hz)
An average finger snap takes 100-150ms. The frequency set to 50Hz gives us 5-8 snaps’ specific points. A rolling window of 16 points used for model training guarantees that any snap fits in this window and we have enough data on both edges to identify specific points.
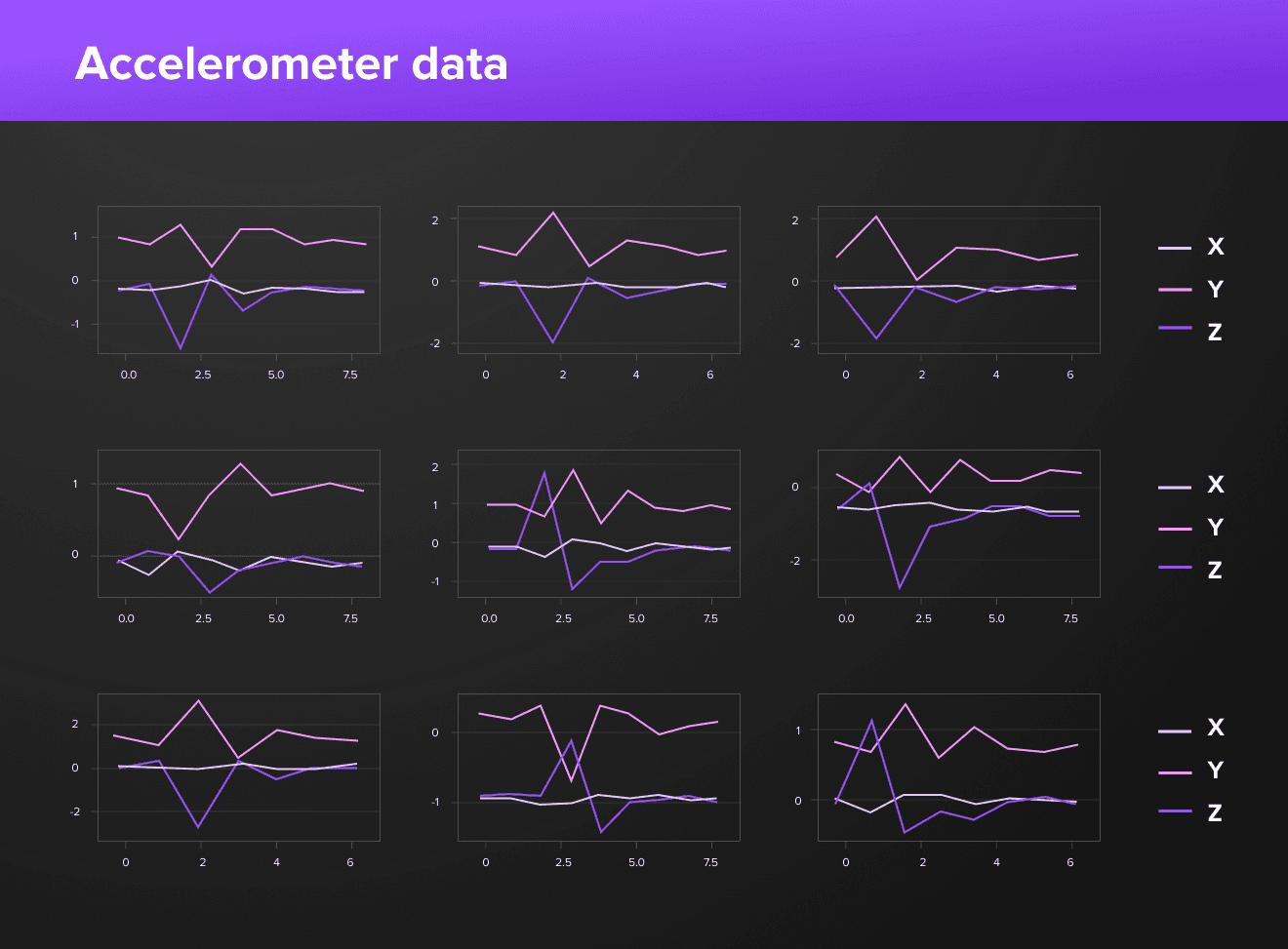
On the above chart you can see how various snaps look on the accelerometer data. Frequency — 50Hz
I started collecting the data, moving from simple cases with a static hand position, to more complex scenarios where I waved my hands like a fly hunter. I soon found out that it’s hard to distinguish snaps from other movements without some type of clue. I adjusted the application to record an audio stream along with the accelerometer data, which simplified the markup process a lot. Audio data is used only for labelling purposes and not included in the model.
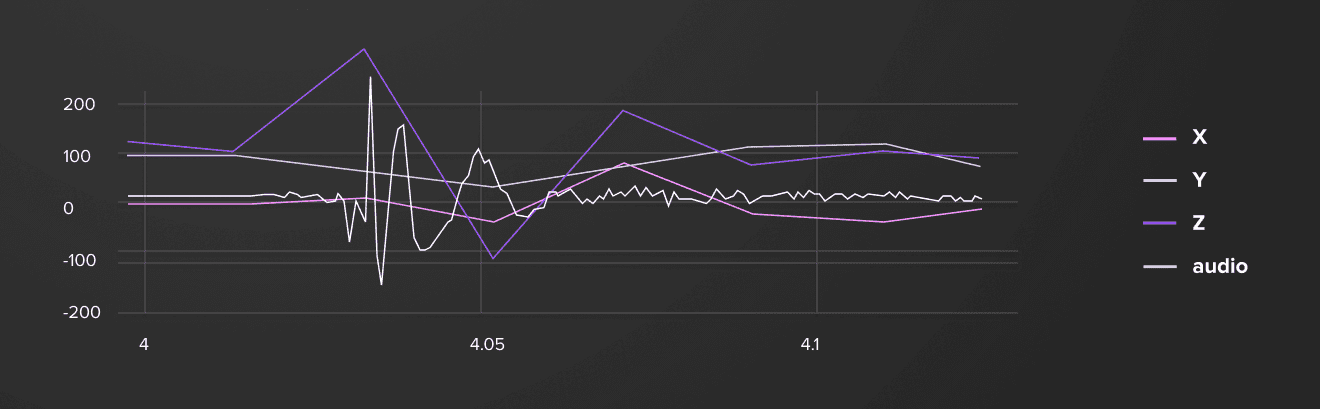
You can see how the audio signal (12KHz / 10) is aligned with accelerometer data.
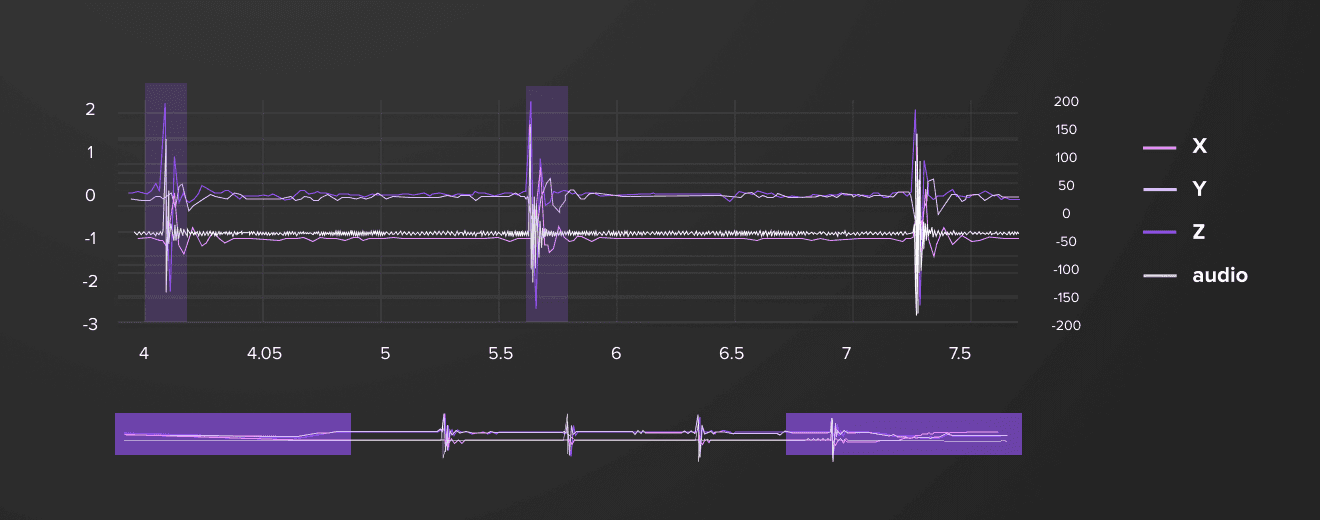
Watch a live demo of the Apple Watch accelerometer data:
Visual labeling tool
One of the downsides of using deep learning is that you need a lot of data to cover diverse scenarios. I created a handy visual labeling tool to precisely markup collected data. It can be easily adjusted to use with any time-series based data and along with other code available in the Github repo.
Control Keynote with Apple Script
Before I dived too deep into the machine learning stuff, I did a quick feasibility check, and verified that it’s possible to manage Keynote slides using SDK. Apple Script allows controlling Keynote from an external application. The following snippet shows how to play the next slide in the presentation. It’s also available on my Github repo.
tell application "Keynote"
activate
try
if playing is false then start the front document
end try
tell the front document
if slide number of current slide is less than slide number of last slide then
show next
end if
end tell
end tellThere is an OS X command (osascript) to run a script from the shell. It needs to be authorized at the first invocation. You can find more information and additional examples on iWork Automation.
Conclusion
In the next part, I’ll show you how to prepare a training dataset, train a Bi-directional Long Short Term Memory (Bi-LSTM) neural network to achieve 99% accuracy and use it in the end-to-end setup to control a Keynote presentation from an Apple Watch using gestures.